CPU can only see the threads
January 23, 2025 · 12 min read · Page View:

Even in different processes, the CPU can only see the threads. ---- My own impression
If you have any questions, feel free to comment below. Click the block can copy the code.
And if you think it's helpful to you, just click on the ads which can support this site. Thanks!
In python, due to the GIL (Global Interpreter Lock), which is a mutex and ensures only one thread can execute at a time, so the multiple threads parallel execution is not supported under the CPython interpreter. But what about the multiple processes? What is the difference between them? How to choose the right method? Do you know the coroutine? Let’s explore it together.
Prerequisite #
To begin with, you should know the basic conceptions:
- Process: The process is the resource allocation unit.
- Thread: The thread is the minimum unit of CPU scheduling.
For every process, the actually execution unit is the main thread in the process. Hence, even in different processes, the CPU can only see the threads.
The core of the computer is the number of physical cores that can be parallelized at the same time (the CPU can only see the threads). Due to the hyper-threading technology, the actual number of threads that can be parallelized is usually twice the number of physical cores, which is also the number of cores seen by the operating system. We only care about the number of threads that can be parallelized, so the number of cores mentioned later is the number of cores seen by the operating system, and the core refers to the core after the hyper-threading technology (not the physical core).
- If the computer has multiple CPU cores, and the total number of threads in the computer is less than the number of cores, then the threads can be parallelized and run on different cores.
- If it is single-core multi-threading, then multi-threading is not parallel, but concurrent, that is, to balance the load, the CPU scheduler will switch different threads on a single core.
- If it is multi-core multi-threading, and the number of threads is greater than the number of cores, some threads will keep switching, and execute concurrently, but the maximum number of parallel execution is actually the number of cores in the current process, so blindly increasing the number of threads will not make your program faster, but will add extra overhead to your program.
Process #
- The process is the resource allocation unit: An process has its own independent running space (including the text region, data region, and stack region).
- Every process has its own independent memory space, which ensures the isolation of memory address spaces between processes.
- Process contains the procedure, data set and PCB(Process Control Block). The related resources will be recorded in the PCB which indicates the resources are occupied.
- A process is the scheduling unit for seizing the processor. The switching of processes requires saving and restoring the CPU state.
- Multiple processes cannot communicate with each other directly. They need a inter-process communication (IPC) mechanism to communicate with each other, which there will be a pipe(in parent-child process) or named pipe or signal or message queue or shared memory(the most efficient way) or socket(even can be used in different machines).
Cons:
- If changes the processes frequently, it will consume more resources. Around GB level.
Thread #
- Thread is a lightweight process, which is minimum unit of CPU scheduling.
- Multiple threads share the same memory space of the process. So the threads can communicate with each other directly.
- The scheduling of threads is smaller than process. The stack is KB level.
- Thread is not related to resource allocation. It belongs to a process and shares the resources of the process with other threads in the process. Threads consist only of the related stack (system stack or user stack), registers, and the thread control block (TCB). Registers can be used to store local variables within a thread, but cannot store variables related to other threads.
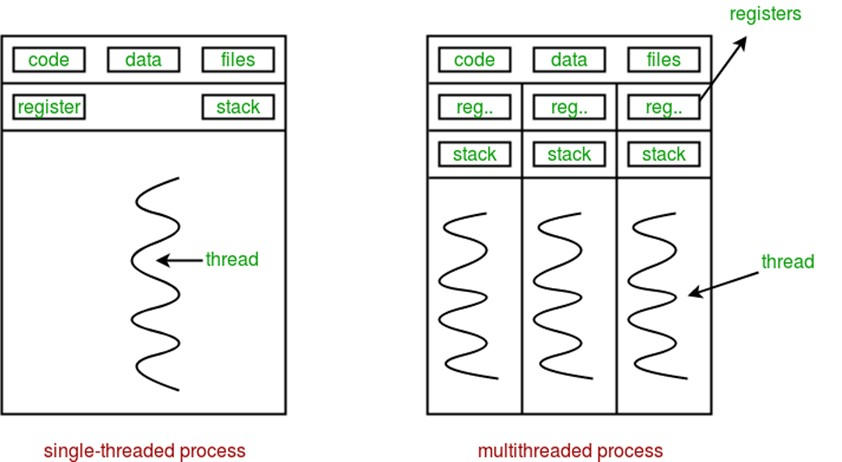
Other comparsion #
- The process is independent of each other, if one process is crashed, it will not affect other processes. But the thread is not independent of each other, if one thread is crashed, it will affect the whole process crashed.
- The process uses memory addresses that can be locked, that is, when one thread uses some shared memory, other threads must wait for it to finish before they can use this memory. (mutex)
Choose #
- For the CPU intensive tasks, recommend to use multiple processes.
- For the IO intensive tasks, recommend to use multiple threads. eg, scratch the web, when IO is blocking in system call, the thread can release the GIL and let CPU run other threads.
- Common usage:
- For the Webserver, which needs to create or close the connection frequently, better use the multiple thread.
- For the strong relationship between the data, better use the multiple threads.
Context switching #
The context switching contains the following three types:
- Process context switching: Switching between different processes. Task scheduling adopts a preemptive method of time slice rotation for process scheduling.
- Thread context switching: Switching between different threads.
User modeandkernel modecontext switching: Switching between user mode and kernel mode. (when user program needs to call hardware devices, the kernel needs to switch theuser programto thesystem call)
The context switching contains the following steps:
- Switch page to use new address space (only for process switching)
- Switch kernel stack and hardware context: The main difference between thread context switching and process context switching is that the virtual memory space of thread switching is the same, but the process switching is different (so the process switching is most expensive). The most cost is the switch of register content.
How to just the bottle neck of context switching? If CPU is running at full load, it should meet the following distribution:
- User Time: 65%~70%
- System Time: 30%~35%(if too high, it means the context switching is too frequent)
- Idle: 0%~5%
Multiple threads #
In other languages, multiple threads can run in multiple cores. But in python, multiple threads can only run in one core at the same time.
In python, there is a GIL (Global Interpreter Lock) which only allows one thread to execute in the CPU. And the python has different interpreters, such as:
- CPython: the official implementation which is written in C.
- Jython: compile the python code to java bytecode and run it in JVM.
- IronPython: .NET platform.
- PyPy: RPython.
Only the CPython has the GIL, and the process of releasing the lock is time-comsuming. So in the multiple cores the performance of the Python is not good.
The official docs: This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
In other words, if there is no GIL, probably the garbage collection mechanism will directly recycle the variables of the code that is being executed by multiple threads, which will cause the program to crash. So the GIL is added in the CPython to ganruntee the security of thread’s level. Only the thread obtains the GIL first, then to obtains the CPython interpreter.
Why only CPython has the GIL? #
The Python is interpret language, so it cannot know the global of whole code. Only has the GIL can access to the CPython.
But Java is a hybrid language, so in the Jpython there is no GIL.
Compiled languages: the compiler make the code to the binary bytescode which can run on the machine directly. But you should compile it into different platform binary executable. Some common languages: C, C++, go, Pascal, Object-C and Swift.
Interpreted language: First, translate it into intermediate code, and then let the interpreter interpret and run the intermediate code. The source program is translated into machine code during the running process. One sentence is translated and then executed until the end. It has good platform compatibility and can run in any environment, provided that an interpreter (virtual machine) is installed. Some common languages: JavaScript, Python, Erlang, PHP, Perl, Ruby.
Hybrid language: In C#, instead of directly compiling into machine code during compilation, it compiles into intermediate code. The.NET platform provides a Common Language Runtime (CLR) to run the intermediate code. The CLR is similar to the Java Virtual Machine (JVM). After C# code is compiled into Intermediate Language (IL) code, it is saved in a DLL. When the program runs for the first time, the Just-In-Time (JIT) compiler compiles the IL code into machine code and caches it in memory, and subsequent executions can directly use this cached machine code. As for Java, it can be considered a compiled language. All Java code needs to be compiled; a
.javafile is useless without compilation. Regarding the efficiency of the JVM, there are optimization techniques such as JIT and Ahead-Of-Time (AOT). Java can also be considered an interpreted language. Since Java code cannot run directly after compilation, it is interpreted and run on the JVM, so it is interpreted.
What is thread security? #
The thread security is mainly about the memory security.
In the memory space of each process, there is a special common area, usually called the heap (memory). All threads within the process can access this area, which is the potential cause of problems. In the absence of a protection mechanism, the heap memory space is an unsafe area for multithreading. This is because the data you put into it may be “adjusted” by other threads.
The multiple thread in python #
So in the python, we can use the threading module to create the thread.
# directly usage
import threading
def run(n):
print("current task:", n)
if __name__ == "__main__":
t1 = threading.Thread(target=run, args=("thread 1",))
t2 = threading.Thread(target=run, args=("thread 2",))
t1.start()
t2.start()
# customize class usage
import threading
class MyThread(threading.Thread):
def __init__(self, name):
super(MyThread, self).__init__() # initialize the parent class
self.name = name
def run(self):
print("current task:", name)
if __name__ == "__main__":
t1 = MyThread("thread 1")
t2 = MyThread("thread 2")
t1.start()
t2.start()
# Let the main thread wait for the sub-thread to complete
if __name__ == "__main__":
t1 = threading.Thread(target=count, args=("100000",))
t2 = threading.Thread(target=count, args=("100000",))
t1.start()
t2.start()
# use .join() to wait for the sub-thread to complete
# if the t1 is very time-comsuming, you can set the timeout
# t1.join(timeout=5) to prevent the t2.join() from being blocked
t1.join()
t2.join()
# The Daemon thread is opposite to join(), it will ensure the sub-thread follows the main thread
t1.setDaemon(True)
t1.start()
Timer
def show():
print("Pyhton")
t = threading.Timer(1, show) # set the thread start 1 second later
t.start()
But how to let each thread use their own data? Use the threading.local() to create the thread-local storage.
import threading
# Create the global object
local_school = threading.local()
def process_student():
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# Bound the object separately
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
Thread Synchronization and Lock #
# create the Lock
mutex = threading.Lock()
# Allow the the thread obtain the lock again when it already holds the lock
# Same methods as the Lock
Reentrant = threading.RLock()
# obtain the lock
mutex.acquire([timeout])
# release the lock
mutex.release()
# allow multiple threads to obtain the lock
semaphore = threading.BoundedSemaphore(5)
# acquire the lock
semaphore.acquire([timeout])
# release the lock
semaphore.release()
The multiple process in python #
The usage is similar to the thread.
# similar usage, omit here
from multiprocessing import Process
def show(name):
print("Process name is " + name)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
Queue #
from multiprocessing import Process, Queue
def put_in_queue(queue):
queue.put('Queue') # put() means put the data into the queue
if __name__ == '__main__':
queue = Queue()
pro = Process(target=put_in_queue, args=(queue,))
pro.start()
print(queue.get()) # get() means get the data from queue
pro.join()
# Common usage
Queue.qsize()
Queue.empty()
Queue.full()
Queue.get([block[, timeout]])
Queue.get_nowait() # == Queue.get(False)
Queue.put()
Queue.put_nowait(item) # == Queue.put(item, False)
Queue.task_done() # send a signal to the queue
Queue.join() # wait until the queue is empty(similar to thread.join())
Pipe #
The essence is communication rather than share the data. Just likes the socket.
Main use: send() and recv()
from multiprocessing import Process, Pipe
def show(conn):
conn.send('Pipe')
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
pro = Process(target=show, args=(child_conn,))
pro.start()
print(parent_conn.recv())
pro.join()
Manager #
https://docs.python.org/3.6/library/multiprocessing.html#managers[1]
Pool #
apply(): synchronous(serial) blockingapply_async(): asynchronous(parallel) not blockingterminate(): terminate the poolclose(): wait for the pool to complete then close the pooljoin(): must add afterclose()orterminate()
#coding: utf-8
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
# the pool is 3
# only 3 processes is running at the same time
pool = multiprocessing.Pool(processes = 3)
for i in range(5):
msg = "hello %d" %(i)
# non-blocking, the sub-process will not affect the main process execution, main process will run to pool.join()
pool.apply_async(func, (msg, ))
# blocking, first execute the sub-process, then execute the main process
# pool.apply(func, (msg, ))
print("=================")
# before calling join, you must call close function, otherwise it will be wrong.
pool.close()
# after calling close, there will be no new process added to the pool
# join function will wait for all sub-processes to complete
# !important: if not join, there will be 5 zombie processes
pool.join()
print("Sub-process(es) done.")
Coroutine #
When async operations share the resources, the coroutine which defined by user based on time slice is better than threads based on Preemptively. The coroutine has its own register context and stack, which is more lightweight than the thread, the stack is KB level. In python, the coroutine is single thread, which means there only be one coroutine running at the same time, there won’t be conflict in variable. So the coroutine is safe.
import asyncio
balance = 0
async def change_it_without_lock(n):
global balance
balance = balance + n
# Besides the time slice, you can also use the `await` to surround the "right" actively.
await asyncio.sleep(1)
balance = balance - n
print(balance)
# if you call the `change_it_without_lock()` function directly, the return is a coroutine object.
# so if you want to run it directly, you should use the `await` or `asyncio.run(function)`
loop = asyncio.get_event_loop() # get the event loop
res = loop.run_until_complete(
asyncio.gather(change_it_without_lock(10), change_it_without_lock(8),
change_it_without_lock(2), change_it_without_lock(7)))
print(balance)
# 17
# 9
# 7
# 0
# 0
# As we can see above, the process is not consistent, but the result is consistent.
# that is easy to understand, the 10 is +10 but await the sleep, then the 8 is running, and the same until 10+8+2+7=27, then the 10 sleep is over, then -10, print 17, and recursively 9 7 0, finaly is 0.
All in all, if the coroutine is not use await to surround the “right” actively, the coroutine is safe. If you use await, the result will be consistent. If you want to make the process consistent, you can only use the Lock. But in this situation, the async will be sync.
Reference #
https://stackoverflow.com/questions/49090416/why-is-the-python-interpreter-not-thread-safe[2]
https://www.cnblogs.com/lizexiong/p/17141988.html[3]
https://liaoxuefeng.com/books/python/process-thread/process-manager/index.html[4]
https://www.cnblogs.com/v3ucn/p/16530665.html[5]
https://zhuanlan.zhihu.com/p/82123111[6]
References
- https://docs.python.org/3.6/library/multiprocessing.html#managers ↩︎
- https://stackoverflow.com/questions/49090416/why-is-the-python-interpreter-not-thread-safe ↩︎
- https://www.cnblogs.com/lizexiong/p/17141988.html ↩︎
- https://liaoxuefeng.com/books/python/process-thread/process-manager/index.html ↩︎
- https://www.cnblogs.com/v3ucn/p/16530665.html ↩︎
- https://zhuanlan.zhihu.com/p/82123111 ↩︎
Related readings
- The Encode and Decode in Python
- The Instance Class Static Magic Method in Python
- How to Publish Your Code as a Pip Module
- Python Generator Iterator and Decorator
- Python Underlying Mechanism
If you want to follow my updates, or have a coffee chat with me, feel free to connect with me: